代码证据:FlashMLA 中的 Model1
来自 FlashMLA 源代码库的直接证据,展示 Model1 的实现。
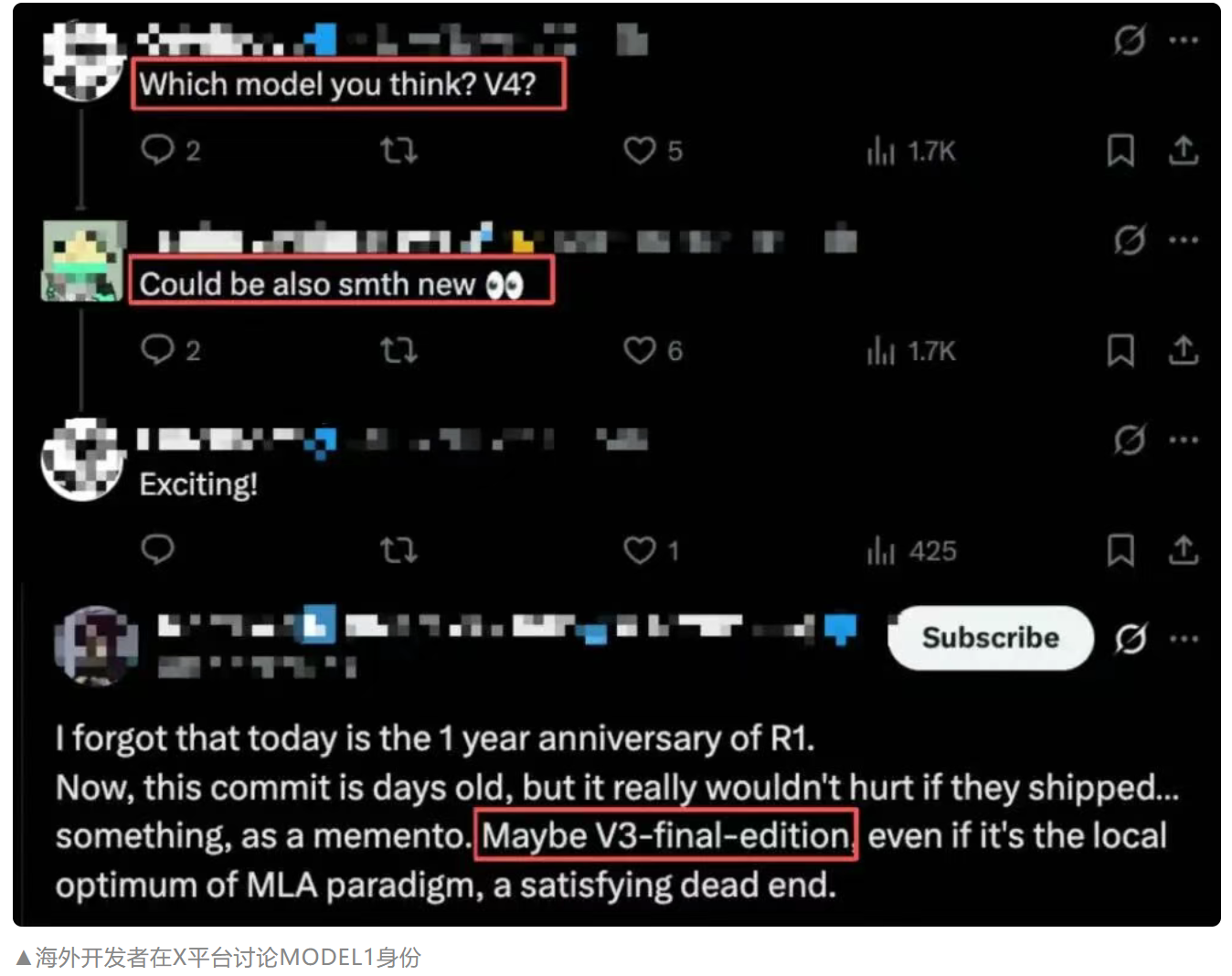
ModelType::Model1 引用
直接代码引用显示 Model1 是一个具有专用实现路径的独特模型类型。
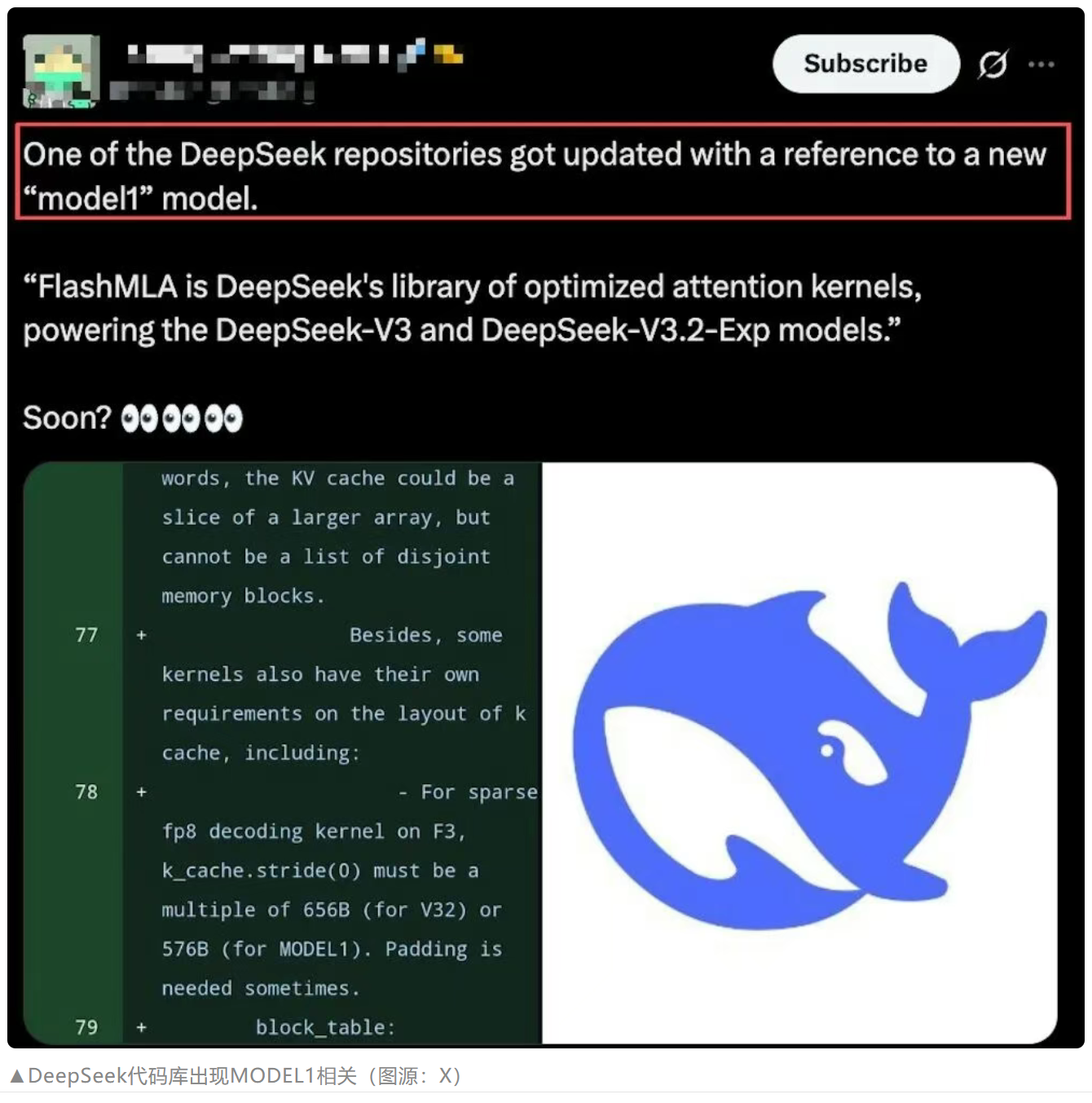
持久化内核文件结构
Model1 持久化内核文件与 V3.2 版本并行存在,表明独立的编译路径。

内存对齐注释
代码注释揭示了 Model1 KV 缓存的 576B 步长要求(后从代码库中删除)。
2025年1月9日
外媒首次报道 DeepSeek 下一代模型开发,引用知情人士消息。
2025年1月21日
FlashMLA 代码库更新揭示 Model1 代码引用,引发社区讨论。
当前
开发者继续分析代码结构;内存对齐注释已从代码库中删除。

