Code Evidence: MODEL1 in FlashMLA
Direct evidence from the FlashMLA source code repository showing MODEL1 implementation.
ModelType::MODEL1 References
Direct code references showing MODEL1 as a distinct model type with dedicated implementation paths.
Persistent Kernel File Structure
MODEL1 persistent kernel files exist parallel to V3.2 versions, indicating independent compilation paths.

Memory Alignment Annotation
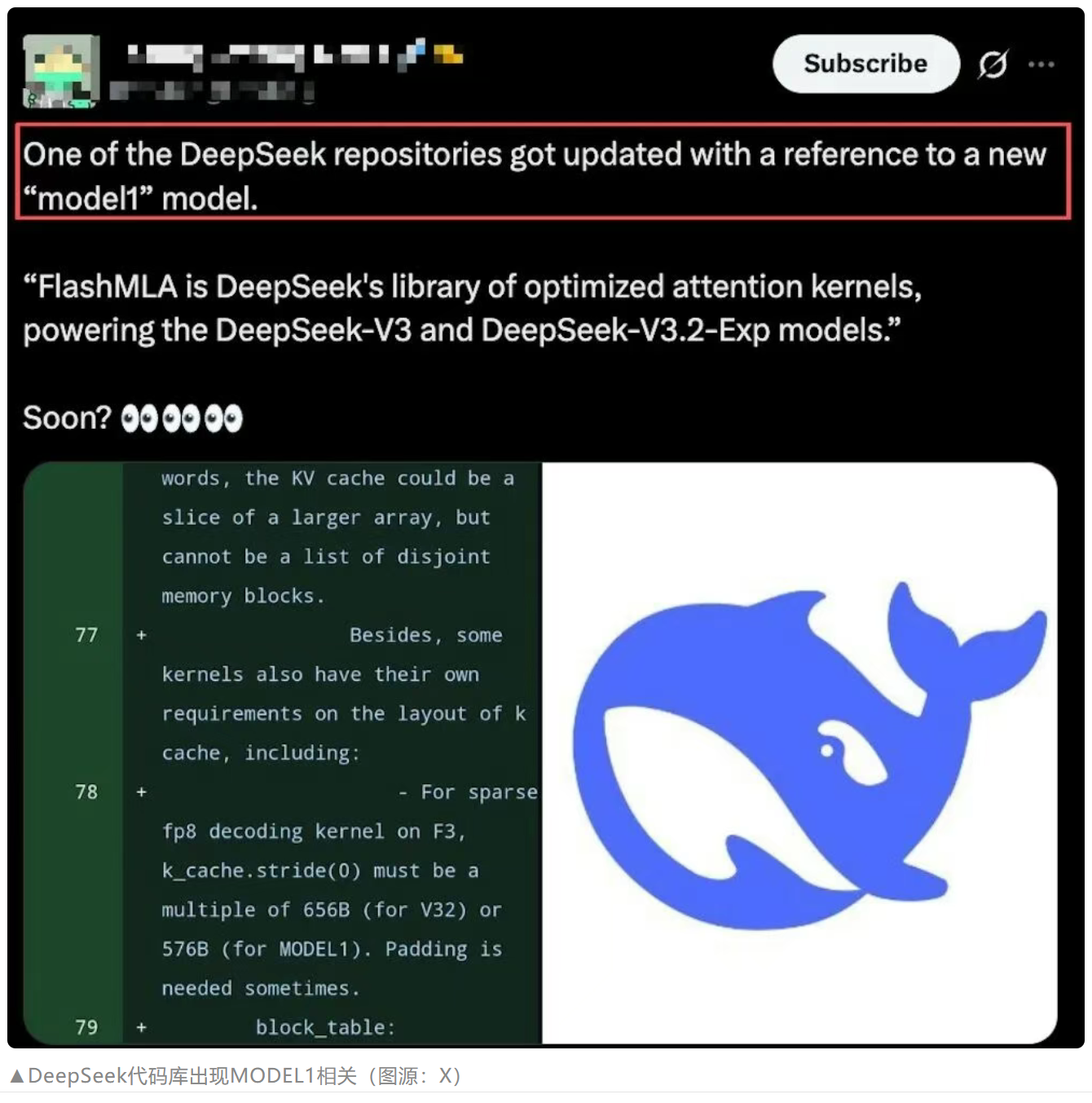
Code comments reveal 576B stride requirement for MODEL1 KV cache (later deleted from repository).
January 9, 2025
Foreign media first reported DeepSeek's next-generation model development, citing insider sources.
January 21, 2025
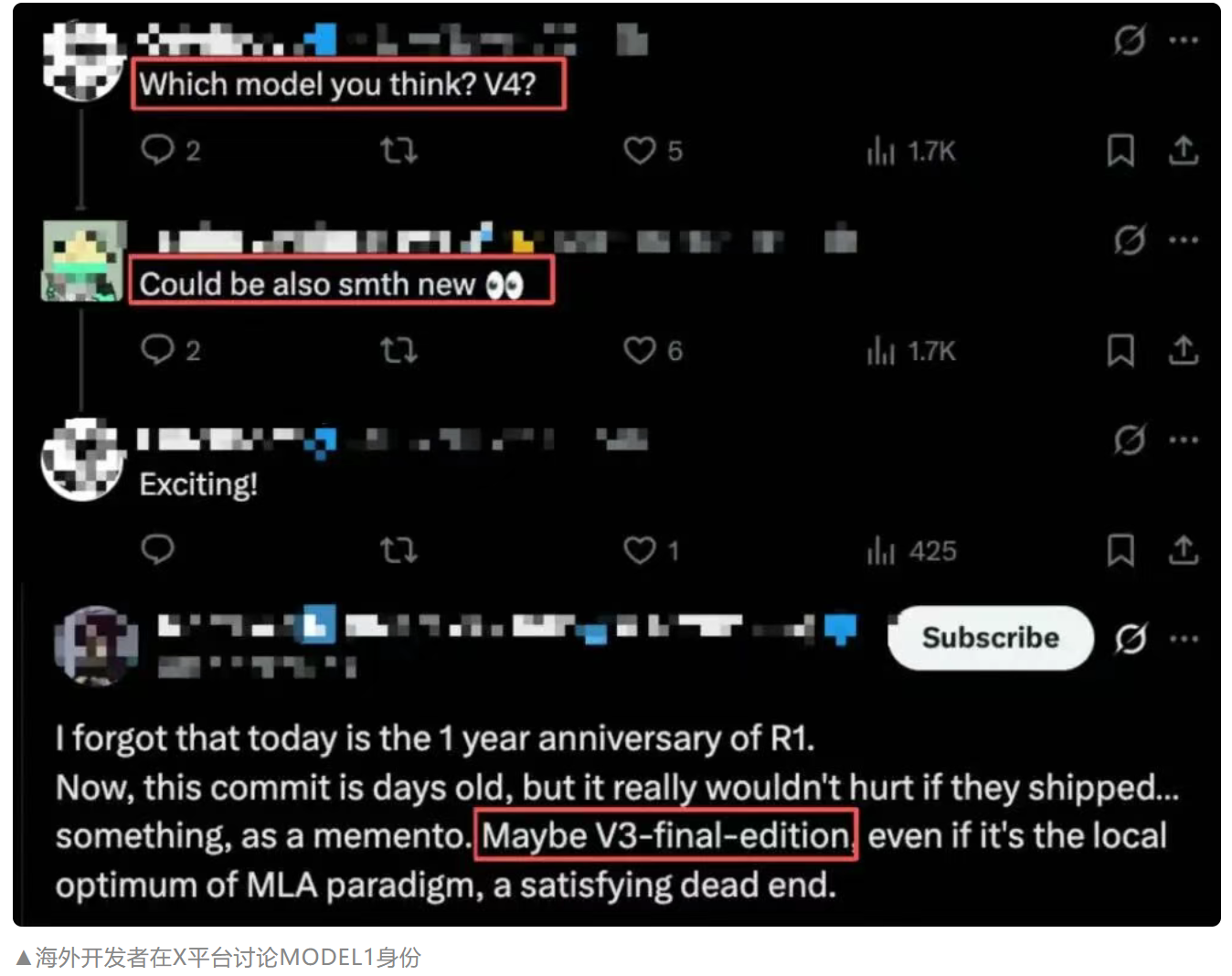
FlashMLA repository updates reveal MODEL1 code references, sparking community discussion.
Current
Developers continue analyzing code structure; memory annotation deleted from repository.

